
Deep Appearance Models
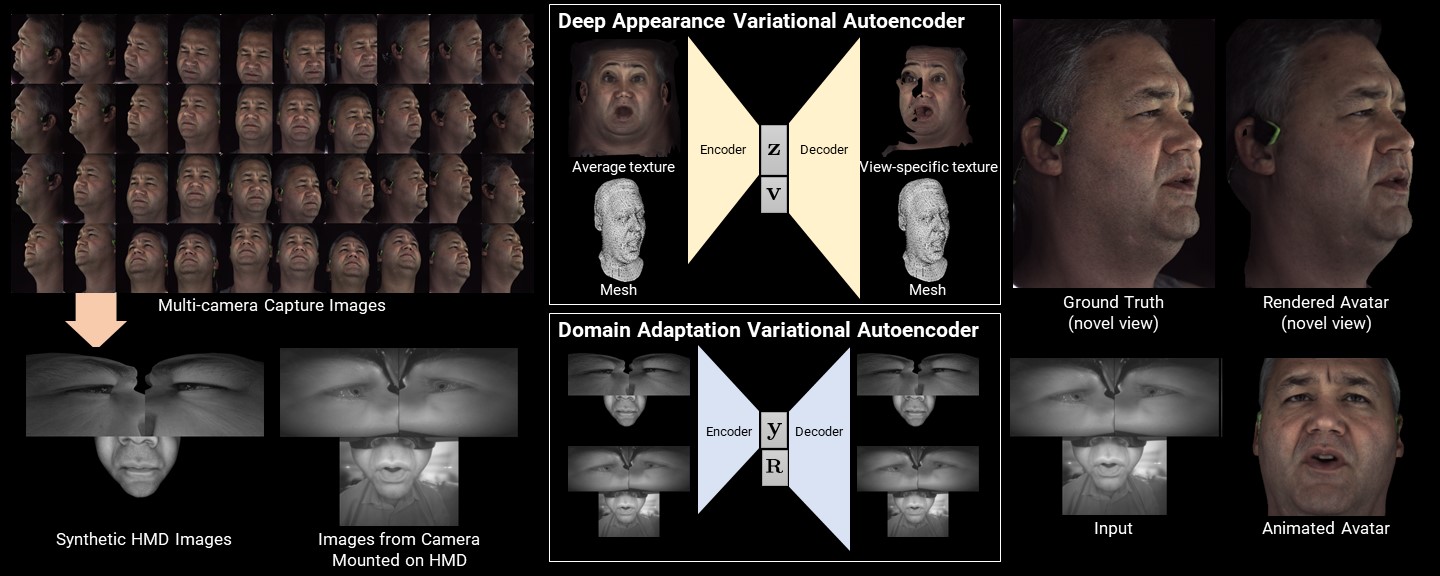
Deep Appearance Models is a method for taking multi-view capture data and creating photorealistic faces that are driveable from cameras mounted on a VR headset. The method consists of two parts. The first is a variational autoencoder to output mesh vertex positions and a 1,024 x 1,024 resolution texture map represented by a small latent code that describes the expression and state of the face. The second part is a method to correspond multi-view capture data and images captured from cameras mounted on a virtual reality headset using a domain adapting variational autoencoder. We combined these two pieces into a real-time system that enables realistic face-to-face conversations in VR.
Example Results


Bibtex
@article{Lombardi:2018,
author = {Lombardi, Stephen and Saragih, Jason and Simon, Tomas and Sheikh, Yaser},
title = {Deep Appearance Models for Face Rendering},
journal = {ACM Trans. Graph.},
issue_date = {August 2018},
volume = {37},
number = {4},
month = jul,
year = {2018},
issn = {0730-0301},
pages = {68:1--68:13},
articleno = {68},
numpages = {13},
publisher = {ACM},
address = {New York, NY, USA},
}
Related Papers
Check out our follow-up work here